
Hardware vulnerabilities in cloud-native environments
The Spectre/Meltdown family of information disclosure vulnerabilities—including the more recent L1 Terminal Fault (aka “Foreshadow”)—are a new class of hardware-level security issues which exploit optimizations in modern CPUs that involuntarily leak information. This potentially has a subtle impact on container workloads, particularly in a virtualized environment. This post will look at the individual OS abstraction levels of a generic container stack, and discuss risks and mitigations in a variety of scenarios. Let’s start with describing what we’ve labelled “generic container stack” above. We’ll use this model throughout the document to illustrate various threat scenarios. Whether we operate our own infrastructure (bare metal, VMWare, OpenStack, OpenNebula, etc.), or are customers of an IaaS (GCE, EC2) or PaaS (GKE, AKS) offering, we should know the implications of Spectre/Meltdown to the stack we are using. This will allow us to ensure the security of our cluster, be it through direct action, or through qualified inquiries to our service providers. Meet our stack:
![]()
At the lowest level is your application, as our smallest - atomic - unit.

Typically, we deal with individual applications running with container isolation. Nothing much changes in our picture so far.

To run workloads in parallel, operators may opt to put a number of containers into a sandbox, most commonly a virtual machine. Virtualization, apart from isolation, also abstracts from the hardware level, easing maintenance operations. Some implementations skip this virtualization layer - we’ll look at the implications (not necessarily negative) further below.
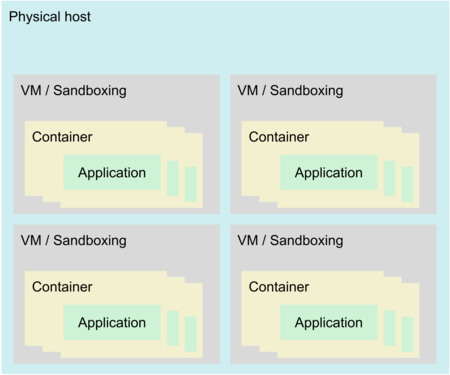
IaaS operators aim to consolidate their physical hardware, so bare metal hosts are filled with a number of sandboxes to saturate CPU and I/O.
While sandboxing traditionally isolates containers from traditional attacks that exploit flaws in applications’ implementations, the underlying physical host’s CPU introduces new attack vectors.
A brief recap of Meltdown, Spectre, L1TF, and related attacks
Now that we have a mental model of our target environment, let’s consider the actual class of attacks we’re dealing with. Spectre, Meltdown et al. are a new category of security vulnerabilities that exploit side effects of CPU optimizations for code execution and data access. Those optimizations—speculative execution of instructions—were originally meant to run hidden, without any user-visible impact on CPU execution states. In 2018, the general public learned that there are indeed observable side effects, exploitable by priming a CPU’s speculative execution engine. This creates a side channel for the attacker to draw conclusions on the victim’s workload and data.
While we will only briefly discuss the attacks, Jon Masters’ presentation and slides on Spectre/Meltdown provide an excellent and thorough introduction.
The family of attacks work against applications that run on the same core as well as applications running on the other sibling of a hyperthreaded core. It requires exploitable segments suitable for leaking information (“gadgets”) in the victim’s code. Overall, the family of hardware information disclosure vulnerabilities, so far, includes:
- v1, the original
- v2, with branch prediction priming independent from the code attacked
- v3 and v3a aka “Meltdown”
- v4, bypassing stores and leaking “scrubbed” memory
- Level 1 Terminal Fault, or “Foreshadow”
How does this work?
Imagine you have a “shadow CPU” that mimics your real one. To be precise, the shadow only executes load and store memory instructions but no arithmetic instructions. Shadow executes loads from memory before your real CPU gets to see those load instructions, while the real CPU is busy performing arithmetic instructions. Shadow loads very aggressively even in cases where it is likely, but not guaranteed, that the load is even necessary. Its motivation is to make data available in the CPU caches (fast access) instead of making the real CPU walk to memory (orders of magnitude slower). Eventually, the execution flow of the real CPU arrives at where the shadow already is - and the data it needs is readily available from the CPU caches. If the shadow CPU was wrong with its speculation, there’s no harm done since values in the cache cannot be read. Harm is done though when code uses the data loaded to calculate an address in a follow-up load instruction:
if (offset < uper_bound_of_memory_allowed_to_access) { // attack uses offset > allowance
char secret_data = *(char *)(secret_memory_ptr+offset); // never reached by “real” CPU
unsigned long data2 = my_own_array[secret_data]; // never reached by “real” CPU
}
// TODO: use cache timing measurement to figure out which index of “my_own_array” was loaded
// into cache by “shadow”. This will reveal “secret_data”.
Spectre - the keyhole
The Spectre family of attacks—which includes Meltdown, discussed below—allow an unprivileged attacker to access privileged memory through speculative execution. Privileged memory may be OS (kernel) memory of its own process context, or private memory belonging to another application, container, or VM.
Spectre v1
The attack works by first training the branch predictor of a core to predict that specific branches are likely to be taken. A branch in this case is a program flow decision that grants or denies execution of sensitive code based on a value provided by the attacker—for instance, checking if an offset is within a legally accessible memory range. Branch predictor priming is achieved by performing a number of “legal” requests using valid offsets, until the branch predictor has learned that this branch usually enters the sensitive code. Then, the attacker attempts an illegal access as outlined above which will be denied. ut at that point, the speculative execution engine will have executed the access, using an illegal offset, and contrary to its design goal can be forced to leave an observable trace in the core’s cache. The sensitive code is speculatively executed because the branch predictor has seen that branch go into the sensitive code so many times before. But we cannot access the cache, so what gives?
The attacker’s code, while incapable of accessing the privileged data directly, may use it in a follow-up load operation, e.g. as an offset to load data from valid memory. Both reading the privileged data (I) and accessing a place in the attacker’s valid memory range using that privileged data as an offset (II) will be speculatively executed. After the illegal access has been denied, the attacker checks which memory offset from (II) is now cached. This will reveal the offset originating from (I), which reveals the privileged data.
Spectre v2
Spectre v2 builds on the fact that for indirect branches the branch predictor uses the branch target’s memory addresses to keep track of probabilities for indirect branches, and that it uses the virtual addresses of branch targets. The attacker can thus train the branch predictor to speculatively execute whatever is desired by crafting an environment that’s reasonably similar to the victim code in the attacker’s own virtual address space. This means the attacker can prime the branch predictor without ever calling the actual victim code. Only after priming is finished will the victim code be called, following a scheme similar to v1 to extract information. This lowers the restrictions of Spectre v1 with regard to exploitable victim code and makes the Spectre attack more generic and flexible.
Attacker Code:
if (my_offs < my_value) { // branch located at a similar vmm address as
nop; // the code we later attack; we run this branch often,
} // w/ legal offset, until priming completed
Victim Code (“gadget”):
if (offset < uper_bound_of_memory_allowed_to_access) { // victim code, called ONCE, w/ bad
char secret_data = *(char *)(secret_memory_ptr+offset); // offset - “real” doesn’t branch
unsigned long data2 = my_own_array[secret_data]; // but “shadow” already spoiled cache
}
// TODO: use cache timing measurement to figure out which index of “my_own_array” was loaded
// into cache by “shadow”. This will reveal “secret_data”.
Spectre v4 and the SPOILER attack
While v3 is discussed below, Spectre v4 only works when the attacker’s code runs in the same address space as the victim code, but with some extra features. Spectre v4 leverages the fact that speculative reads may return “old” memory contents that have since been overwritten by a new value, depending on the concrete CPU series’ implementation of speculative reads. This allows “uninitialized” memory to be recovered for a brief amount of time even after it was overwritten (e.g. with zeroes). Concrete applications of Spectre v4 include recovering browser state information from inside a browser’s javascript sandbox, or recovering kernel information from within BPF code.
SPOILER, a recently disclosed attack, makes extended use of speculative read and write implementations and the fact that only parts of the actual virtual memory address are being used by the speculative load/store engine. The engine would consider two different addresses to be the same because it does not consider the whole of the address, leading to false positives in dependency hazard detection. SPOILER leverages this to probe the virtual address space, ultimately enabling user space applications to learn about their virtual->physical address mapping. Since the advent of ROWHAMMER, which lets attackers flip DRAM memory bits by aggressively writing patterns in neighboring memory rows, virt->phys mappings are considered security sensitive. Consequently, SPOILER, after learning about its address mapping, applies ROWHAMMER and can this way change memory contents without accessing it.
Meltdown (Spectre v3) - the open door
Meltdown is a variant of Spectre that works across memory protection barriers (Spectre v3) as well as across CPU system mode register protection barriers (Spectre v3a). While v1 and v2 limit the attack to memory that’s valid in at least the victim’s process context, Meltdown will allow an attacker to read memory (v3) and system registers (v3a) that are outside the attacker’s valid memory range. Accessing such memory under regular circumstances would result in a segmentation fault or bus error. Furthermore, Meltdown attacks do not need to involve priming branch predictors - these go straight to the price of reading from memory that should be inaccessible. For illustration, the following construct will allow arbitrary access of memory mapped into the address space of the application—for instance, kernel memory where a secret is stored that should be inaccessible to user space:
char secret_data = *(char *)(secret_kernel_memory_ptr); // this will segfault
unsigned long data2 = my_own_array[secret_data]; // never reached, b/c segfault
// TODO: catch and handle SIGSEGV
// then use cache timing measurement to figure out which index of “my_own_array” was loaded
// into cache by “shadow”. This will reveal secret_data.
The Meltdown attack is based on lazy exception checking in the implementation of speculative execution in most Intel CPUs since 2008 (newer series initially released in 2019 and newer should work around this issue), as well as some implementations of ARM CPUs. When speculatively executing code, exceptions are not generated at all (making the speculative execution engine more lightweight). Instead, the exception check only happens at speculation retirement time, i.e. when the speculation meets reality and is either accepted or discarded.
With Meltdown—and contrary to Spectre v1 and v2—an attacker can craft their own code to access privileged memory (e.g. kernel space) directly, without requiring a suitable privileged function (“gadget”) to exist on the victim’s side.
Level 1 Terminal Fault - the (virtual) walls come down
L1TF once more leverages a CPU implementation detail of the speculative execution engine and also does not rely on branch prediction, so it is pretty similar to Meltdown. It works across memory boundaries and it bypasses virtualization. In fact, an L1TF attack is most powerful when attacking a bare metal host from within a virtual machine of which the attacker controls the kernel. The most basic L1TF attack would have an attacker’s application allocate memory, then wait for the memory pages to be swapped to disk—which will have the kernel’s memory management flip the “invalid” bit in the respective page’s control structure. The “invalid” bit in those control structures—which are shared between the kernel and the CPU’s hardware memory management unit—should cause two things: the page table entry being ignored by the CPU, and the kernel fetching data from disk back into physical memory if the page is accessed. However, in some implementations of speculative execution (most Intel CPUs from 2008 - 2018), the “invalid” bit is ignored.
When the attacker now reads from memory on that swapped-out page, the speculative execution engine will access actual memory content of a different process, or of the kernel (the content that replaced the attacker’s page after it was swapped to disk), and the attacker can easily retrieve those values by using it as an offset for an operation on their own (not swapped) memory, and then measuring access timings to figure out which value was cached. While this attack is reasonably difficult to mount from an application—the attacker has no control of either the page addresses or when/if the pages are swapped out—it becomes all the worse when mounted from inside a VM.
Inside a (otherwise unprivileged) VM controlled by an attacker, the VM may leverage a CPU mechanism called Extended Page Tables (EPT). EPT allows hosts to share memory management work with guests. This results in a significant performance boost for the virtual memory management, while allowing an attacker to craft suitable page table entries and mark those invalid directly, bypassing the restrictions of the basic attack described above. A malicious VM exploiting L1TF would be able to read all of its physical host’s memory, including the memory of other guests, with relative ease.
Attack Scenarios
After refreshing our memory on the mechanisms exploited to leak information via otherwise perfectly reasonable optimizations, we’ll go ahead and see how we can apply these attacks to the generic container stack we’ve built in the introduction (which, if you just worked your way through the attack details, must feel like ages ago).
Operating System level

This applies to a scenario where containers are run on bare metal, on a container-centric OS. The OS provides APIs and primitives for deploying, launching, managing, and tearing down containerized applications. Potential victims leaking information to a rogue application would be its own container control plane, the OS part of its process context, and other containers running on the same host. In order to ensure confidentiality, the container OS is required to ship with the latest security patches, and compiled with Retpoline enabled (a kernel build time option).
Furthermore, it would need to have run-time mitigations enabled - IBRS, both (kernel+user space) for Spectre v2, page table isolation (PTI) for Meltdown, store bypass disable (kernel+user space) for Spectre v4, and Page Table Entry Inversion (PTE Inversion) for L1TF.
IBRS is a bit Intel introduced to the machine specific register set of their CPUs.
Security-focused Linux container OSs like Flatcar Linux enable such measures by
default. In order to further secure the container control plane from being
spied on by its own application, the control plane and accompanying libraries
need to be compiled in a way that emits protective instructions around
potential Spectre gadgets (e.g. -mindirect-branch=thunk,
-mindirect-branch-register, -mfunction-return=thunk for gcc).
Virtualization environments
Virtualization environments suffer from an additional vector of attack that makes it significantly easier for the attacker to craft page mappings that exploit L1TF, if the attacker is able to gain control of the guest kernel. We classify virtualization environment in two categories.
Restricted Virtualization environments (“no root”, unprivileged containers)

Restricted virtualization environments, while providing virtualization services to container clusters, restrict access of the virtualization guest - unprivileged users are used for running workloads, and the guest OS kernel cannot be changed by a third party. This approach requires that the operator remains in full control over both VMs and VM guest kernels at any point in time.
Appropriate monitoring needs to be in place to ensure that a malicious application does not break out of its unprivileged container and subsequently receives access rights to mutate kernel code. e.g. by loading custom kernel modules or even booting into a custom kernel. This would ultimately allow attackers to work around the PTE inversion restriction in particular, but with significant security impact.
With full control over VM and instance kernels, the Operating System level mitigations discussed in the previous section will secure the stack.
Unrestricted Virtualization environments (“got root”, privileged containers)

Unrestricted virtualization environments, even when not “officially” allowing for custom kernels, provide root access to 3rd parties and therefore are at risk of mutating changes to the kernel anyway, such as rogue module loads, or even booting a custom kernel. This will allow an attacker to craft custom page table entries, greatly enhancing the impact of the L1TF attack in particular.
From here on, working around those hardware vulnerabilities will hurt performance.
Keeping control of the guest kernel
Before we discuss mitigations for a scenario where we don’t control the guest kernel, let’s have a look at our options for securing control even in privileged environments. This mitigation ensures that the VM kernel cannot be modified—e.g. through loading a kmod—or otherwise mutated, even with VM root access available. A technical way to hide access to the VM kernel provided by some virtualization systems (most notably qemu) is to use direct kernel boot—that is, starting the guest with a kernel that is not on the VM filesystem image, but present on the bare metal virtualization host and is provided to the hypervisor when a VM is started. Since VMs do not have access to host file systems, the VM kernel cannot be modified even if VM root access is available. This approach would require the operator to provide and to maintain custom Linux kernel builds tailored for their infrastructure. Kernel module signing may be leveraged to guarantee “legal” kernel modules can still be loaded. Security in this scenario may be supported by operationalising direct kernel boot with the virtualization stack—i.e. booting the VM into a kernel supplied on the bare metal host instead of from the instance’s file system image, locking down loading of modules (monolithic kernel, or kmod signing), and removing kexec support. Security focused distributions like Flatcar Linux are working towards enabling locked-down kernel configurations like the above.
With the guest kernel remaining firmly under the control of the operator, Operating System level mitigations like PTE inversion (which cannot be worked around from inside the VM’s user space) will once more secure the system.
Pinning VM CPUs (vCPUs) to physical CPUs (pCPU)
In order to have VMs of varying trust levels continue to share the same physical host, we might investigate ensuring that VMs never share the same L1 cache. The technical way to achieve this is vCPU -> pCPU pinning. In this scenario, virtualization workloads must not be CPU over-committed - one virtual CPU equals one physical CPU, and each physical CPU serves the same VM. Application level over-commitment, i.e. running more applications (or containers) inside of a VM than there are CPUs, may be applied to saturate system usage. Alternatively, VMs may be grouped by trust level, and the virtual cores of VMs of the same trust level may be pinned to the same group of physical CPUs. When the guest kernel cannot be controlled and we therefore need to anticipate attacks from the VM kernel, we need to secure the physical host’s OS as well as other VMs running on the same host. L1TF attacks mounted from VM kernels have significantly higher impact than malicious user space applications trying to leverage L1TF. Specific hardware acceleration in a CPU’s memory management unit—EPT from above—allows guests to manage its page tables directly, bypassing the host kernel. EPT, while providing a significant speed-up to VM memory management, poses a potential security risk for the bare metal host’s OS, as page table entries suitable for exploiting L1TF can be crafted directly.
First, we need to take a step back though and reconsider sandboxing as in this scenario containers in the same VM cannot be considered isolated anymore. Isolation now happens solely at the VM level, implying that only containers of the same trust level may share a VM—which is likely to cause repercussions on a clusters’ hardware saturation and maintenance operations. With CPU pinning, a host’s CPUs are statically partitioned into “VM slots”, and there’s a maximum number of VMs that can run on a host to ensure CPUs are never shared between VMs (or between trust levels). CPU pinning allows guest OS kernels to be in control of 3rd parties without impacting the security of other VMs running on the same physical host.
To further secure the operating system of the physical host, which may also
leak information via the L1 data cache when the VM task-switches into the
physical host’s kernel via a hypercall, the L1 data cache needs to be flushed
before the VM context is entered from the host OS. KVM provides a module
parameter / sysctl that will flush caches, via the kvm-intel.vmentry_l1d_flush
option (l1d for level-1 data cache). The option can be set to either “always”
or “cond” (it can also be deactivated by supplying “never”). “always” will
flush the L1 data cache every time a VM is scheduled off a CPU, while “cond”
will try to figure out whether a vulnerable code path was executed and only
flush if required. This option will impact application performance as the L1D
cache will need refilling after each schedule event, which it otherwise would
not—but since refilling will happen from the L2 cache, the overall performance
impact is expected to be mild.
Securing the Virtualization runtime against L1TF
If we cannot control the guest kernel, and if we also cannot pin vCPUs to pCPUs in a way that multiple VMs do not share L1 caches, we need to work around the L1TF hardware vulnerability by use of software mitigations at the virtualization layer—that is, the bare metal host kernel and hypervisor. These mitigations will impact the overall system performance, though the level of impact is application specific. Software mitigation against L1TF is two-fold. Both attack vectors need to be mitigated:
- Secure active VMs against attacks from other VMs being active at the same time
- Secure L1 cache data of VMs that are becoming inactive from the next VM that’s to use the same physical CPU, or by the host OS (see above).
To mitigate 1., either the Hyperthreading or the EPT CPU feature needs to be disabled on the physical virtualization host. While the performance impact is application specific, overall performance gains published at the time the respective technology was introduced suggest it may be less painful to disable Hyperthreading over deactivating EPT. In any case, operators should monitor the impact on their real-life workloads, and experiment with changing mitigations to determine the least painful measure.
In order to prevent data leaks via the L1 cache after a VM was scheduled off a
pCPU, the L1 cache must be flushed before the next VM starts using that pCPU,
similar to the physical OS protection discussed in the previous section. The
same mechanism via KVM’s kvm-intel.vmentry_l1d_flush option applies here.
Future outlook / potential long-term options
Caches and Hyperthreading in particular has been under sustained attack from this new generation of hardware-level information disclosures, with security researchers warning about potential inherent vulnerabilities, and e.g. the OpenBSD distribution disabling Hyperthreading completely for security reasons. However, even when factoring in the vulnerability drawbacks, valid use-cases for hyperthreading remain. For example, a multi-threaded application, which does share its memory with its threads anay, would benefit without being vulnerable per se. However, currently no scheduler exists in the Linux kernel that is advanced enough to perform this level of scheduling—appointing sets of processes or threads to a set of cores or hyperthreads of the same core, while locking out all other processes from those cores.
But something is in the works. A patch-set of no less than 60 individual patches proposed to the Linux kernel’s CFQ scheduler in September 2018 started a discussion about adding co-scheduling capabilities to Linux. While this particular patch-set appears to have been abandoned (with the discussion apparently concluded), the general direction of this work continues to be pursued. More recently the maintainer of the Linux scheduler subsystem, Peter Zijlstra, proposed his own patch series to tackle this feature.
If you need help improving the security of your Kubernetes environment, please contact us at [email protected].