
Tips and tricks for user namespaces with Kubernetes and containerd
I'm very happy to share some tips and tricks for using user namespaces. After working several years on this project, I couldn't be happier about the fact that everyone can use them now!
This blog post focuses on features added in containerd 1.7 and Kubernetes 1.25 or 1.26. If you are using a different stack (like CRIO instead of containerd), some tips here will not be relevant or you might need to make some adjustments.
But let's start from the beginning.
What is a user namespace?
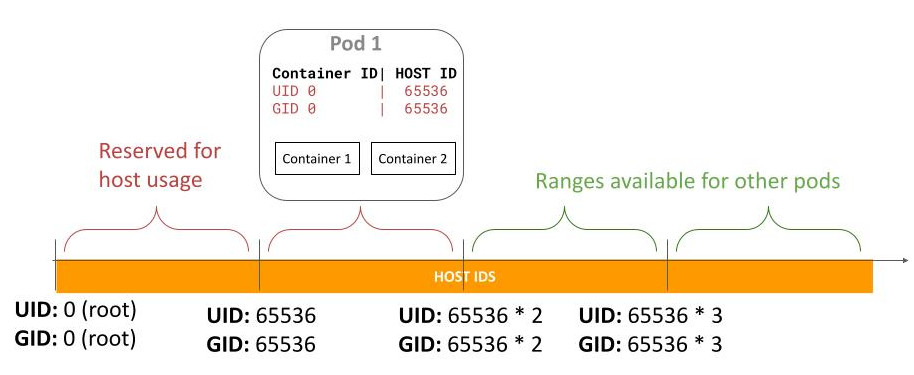
A user namespace is a Linux feature that isolates the user and group identifiers (UIDs and GIDs) of the containers from the ones on the host. The identifiers in the container can be mapped to identifiers on the host in a way where the host UID/GIDs used for different containers never overlap. Furthermore, the identifiers can be mapped to unprivileged non-overlapping UIDs and GIDs on the host. This brings two key benefits:
-
Prevention of lateral movement: As the UIDs and GIDs for different containers are mapped to different UIDs and GIDs on the host, containers have a harder time attacking each other even if they escape the container boundaries. For example, if container A is running with different UIDs and GIDs on the host than container B, the operations it can do on container B's files and process are limited: only read/write what a file allows to others, as it will never have permission owner or group permission (the UIDs/GIDs on the host are guaranteed to be different for different containers).
-
Increased host isolation: As the UIDs and GIDs are mapped to unprivileged users on the host, if a container escapes the container boundaries, even if it is running as root inside the container, it has no privileges on the host. This greatly protects what host files it can read/write, which process it can send signals to, etc. Furthermore, capabilities granted are only valid inside the user namespace and not on the host, which also limits the impact a container escape can have.
Without using a user namespace, a container running as root in the case of a container breakout, has root privileges on the node. And if some capabilities were granted to the container, the capabilities are valid on the host too. None of this is true when using user namespaces (modulo bugs, of course 🙂).
There are many known CVEs (and likely many more as-yet unidentified vulnerabilities) that are partially or completely mitigated by the use of user namespaces.
Demo
As an example, let me show you how user namespaces completely mitigate CVE 2022-0492.
I've created an exploit for Kubernetes that uses a completely regular pod, with no privileges or capabilities, which escapes the container boundaries when user namespaces are not used! This is not possible when we use user namespaces, but let's see it in action:
I expect that user namespaces will mitigate several more CVEs yet to be discovered, as has happened in the last few years while working on this feature.
Limitations in containerd 1.7
Hopefully, I convinced you to try out user namespaces in your cluster. So, before you do that, let me explain the limitations we currently have:
-
It only works with Kubernetes 1.25 and 1.26: this containerd version works, regarding user namespaces support, with Kubernetes 1.25 and 1.26. The runtime changes to support Kubernetes 1.27 or greater are merged for the upcoming release 2.0 of containerd.
-
It is not possible to use in pods with volumes: no persistent volume is supported and just a few ephemeral volumes (like configmaps and secrets) are. You can see more details on the Kubernetes 1.27 documentation. This limitation applies to Kubernetes 1.25 to 1.27 and it has been lifted in 1.28. However, as we already mentioned, containerd 1.7 only works with Kubernetes 1.25 and 1.26.
-
It is not possible to use other host namespaces: you can't use user namespaces with pods that use any host namespace. In other words, pods that set any of
hostNetwork,hostIPC,hostPIDtotruecan't enable user namespaces. -
Pod storage and startup-latency overhead: containerd needs to change the ownership of every file and directory inside the container image, during pod startup. This means it has both a storage overhead, as the size of the container image is duplicated each time a pod is created, and a significant impact on container startup latency, as doing such a copy takes time too. This limitation is completely removed in containerd main and will not affect containerd 2.0 (see more details here)
We don't plan to remove the third limitation, and other limitations can't be mitigated and we just need a new upstream release, like the first two. However, as containerd 2.0 isn't released and, as of writing (November 2023), does not yet have a planned release date, this post explains some tips and tricks to mitigate the fourth limitation while waiting for the new major containerd release.
Mitigating container image duplication size
Container runtimes on Linux use overlayfs as the filesystem for the container image. This allows runtimes to not duplicate the space each time we start a pod using the same image. Each time a pod is started on a node that already has that image, overlayfs allows us to start a new pod without duplicating that image.
Overlayfs allows us to reuse the existing copy of the image and have copy-on-write semantics for the changes we might do in the pod, that is: we only account for the storage of the changes to the container image once the pod was started.
When user namespaces are in the picture, as the users inside the container are mapped to different users on the host, we need each pod to use different permissions for the base image. This is needed so the user in the container can read the files in the container image.
That is also the reason why containerd 1.7 just does a recursive chown of the container image for each pod with user namespaces: so the container with user namespaces can read the files in the container image.
However, thanks to overlayfs we can do some tricks to reduce the storage
overhead and the startup latency. As we only need to change the UID/GID of the
files, not its content, we can mount the overlayfs for the container using the
kernel option metacopy. This means that we only create
a new inode (with the new UID/GID) but do not duplicate the content of the
files in the container image.
Therefore, instead of copying each file (metadata and its content) on container startup, we can use this option and only create a new inode with the metadata, and reference the same content already stored on the disk.
The benefits are huge, as shown in this very interesting blog post from my co-worker Fu Wei:
| Image | Size | Inodes | Overlayfs without metacopy | Overlayfs with metacopy |
|---|---|---|---|---|
| tensorflow/tensorflow:latest | 1489MiB | 32596 | 54.80s | 1.29s |
| library/node:latest | 1425MiB | 33385 | 52.86s | 1.18s |
| library/ubuntu:22.04 | 83.4MiB | 3517 | 5.32s | 0.15s |
As you can see, pods can start roughly 42 times faster by just using this kernel parameter. And there is no storage overhead, although we are using significantly more inodes now.
How do you configure containerd to use this feature?
Containerd will just honor the parameters we set for the overlayfs module. So we can just set
/sys/module/overlay/parameters/metacopy to Y and that will be used by containers created by
containerd after we set the parameter.
Make sure to do it in a way that is persistent across reboots (how to do this is different on different distros). You may want to increase the max number of inodes the file-system you will use can have (some file-systems support changing this online, others at fs creation time).
Be aware that this setting will be used for all containers, not just containers with user namespaces
enabled. This will affect all the snapshots that you take manually (if you happen to do that). In
that case, make sure to use the same value of /sys/module/overlay/parameters/metacopy when creating
and restoring the snapshot.
Conclusions
While we wait for containerd 2.0 that will remove limitations number 1, 2 and 4, we can take actions to significantly improve upon the existing limitation on the storage overhead and latency startup.
If you plan to use this in production, I hope you find this useful.
Further Details
If you found this interesting, you might like to watch my 2022 KubeCon NA talk about user namespaces: Run As "Root", Not Root: User Namespaces In K8s.
If you want to know more about the Kubernetes implementation and examples of how to use this in your cluster, I recommend you check out the Kubernetes documentation (make sure to check it for the version you are using, as several things change in different Kubernetes releases!). For more details on the containerd parts and node requirements, see the containerd documentation.
If you want to learn more about the changes regarding user namespaces in Kubernetes 1.28, you can check this blog post we wrote.
If you want more low-level details about user namespaces in general, you can read this blog
post from my co-worker Fu Wei. If you want to go even deeper, don't hesitate to go
ahead and read man 7 user_namespaces.